




前言
最近小编在整理之前写过的博客,在这个过程中遇到一个问题就是因为之前已经发表的博客部分没有在本地留存,所以我要搬迁这部分文章的时候就会遇到一个问题,手动复制富文本粘贴在 markdown 中是很麻烦的,会有图片丢失、格式杂乱等各种问题,忙活一圈下来还不如重写。为了彻底解决这个问题,我手动写了一个爬虫脚本,将那些没有源文件的博客批量爬取下来,然后自动转换成 markdown 格式的文档,然后就可以直接使用了。
前期准备
因为我们的脚本是基于 Python 的,所以首先确保您已经安装好了 Python@3 的环境,然后再手动安装这两个库就行。
第一个
安装:pip install newspaper3k
newspaper3k,它是一个专门用来爬取文章的库,其实爬取文章好多爬虫库比如 requests、requests-html、httpx 等都可以实现,之所以选择 newspaper3k,就是因为其针对文章做了专门的适配。比如文章的作者,文章中的静态资源,发表时间等都可以直接爬取。
第二个
安装:pip install html2text
html2text,它是一个可以将 html 转换为文本格式的库,我们使用它就可以方便的将我们爬取的文章 html 内容直接转换为 markdown 格式的文本,然后将其保存到文件中即可。
通过以上思路,我们只需要将这个过程批量自动化,就可以很快地完成我们的任务。
实践部分
爬取文章内容
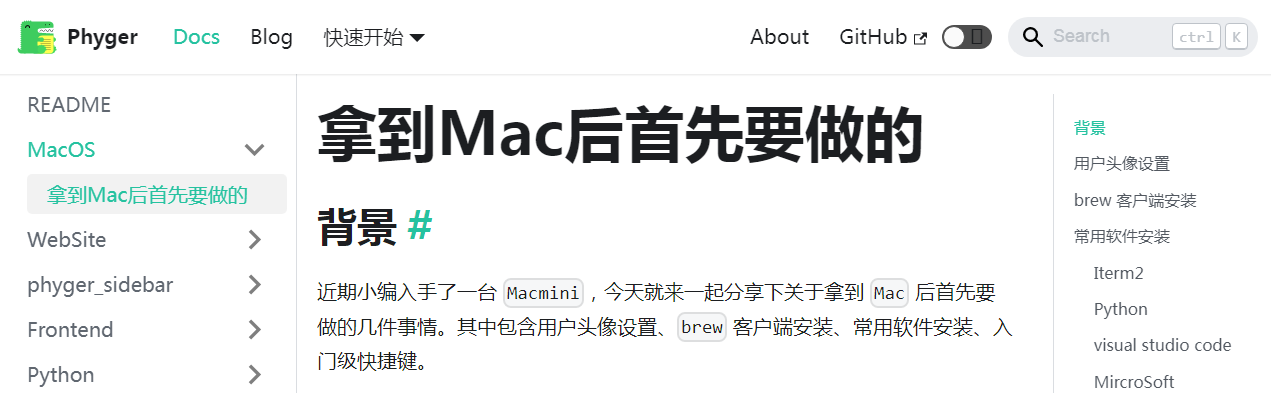
文章原始页面:
代码
from newspaper import Article
# 计划爬取的文章
url = "https://www.u1s1.vip/docs/MacOS/MacOS-1"
# 实例化爬虫对象
article = Article(url,language='zh') # 如果我们想要获取文章的text内容,就需要指定语言为中文
# 将文章内容下载
article.download()
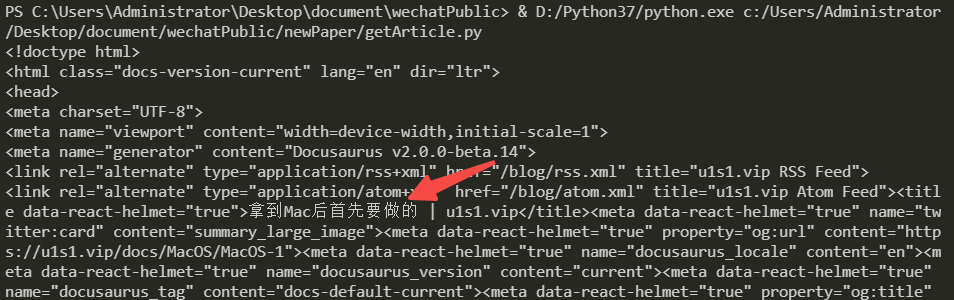
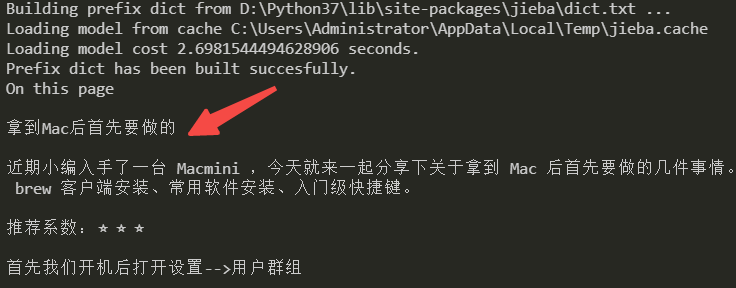
# 查看文章的html内容
print(article.html)
# 格式化内容,方便获取text
article.parse()
print(article.text)
代码运行结果
转换为 markdown
显然,上面爬取的文本无法满足我们的需求,所以我们需要在上面的基础上增加转换为 markdown 的步骤。
代码
from newspaper import Article
import html2text as ht
url = "https://www.u1s1.vip/docs/MacOS/MacOS-1"
article = Article(url)
article.download()
# 获取html内容
html = article.html
# 实例化html2text对象
runner = ht.HTML2Text()
# 转化html为markdown
res = runner.handle(html)
# print(res)
# 将markdown内容保存到res.md
with open ('res.md',mode='w') as f:
f.write(res)
代码执行结果

为什么会报
UnicodeEncodeError呢?因为啊我们在文件写入时涉及到了中文,所以需要声明编码格式为utf-8即可。
修改后的代码
from newspaper import Article
import html2text as ht
url = "https://www.u1s1.vip/docs/MacOS/MacOS-1"
article = Article(url)
article.download()
# 获取html内容
html = article.html
# 实例化html2text对象
runner = ht.HTML2Text()
# 转化html为markdown
res = runner.handle(html)
# print(res)
# 将markdown内容保存到res.md
with open ('res.md',mode='w',encoding='utf-8') as f:
f.write(res)
代码执行结果
结果验证
我们打开 res.md 查看一下
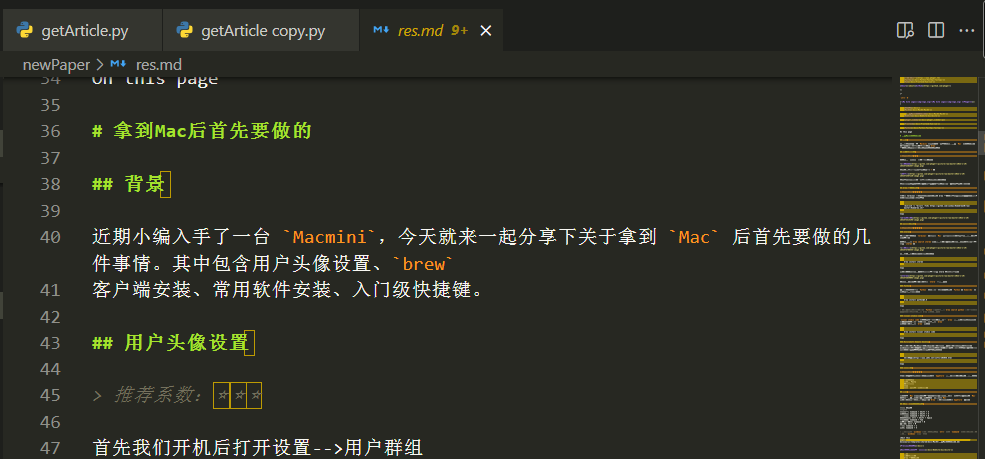
我们可以看到,markdown 内容基本和原文章一致,只是多了部分网站的 header 和 footer,我们将其删掉即可。虽然有很多 markdown 语法不规范的黄色警告,但是并不影响内容的展现,我们预览一下看看效果。
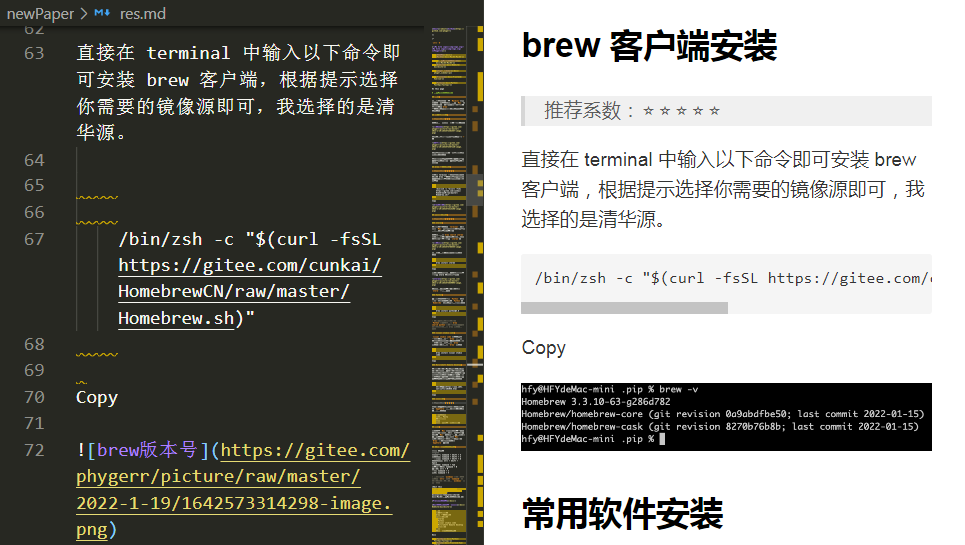
总结
通过以上经历,我们可以确定,这种方式可以完美满足我们的需求。原文章的内容,格式,代码,图床链接等都可以全部获取到。
如果需要处理很多的文章,我们只需要将其存到一个列表中,然后对其循环处理即可。


评论区