




1、前言
前面,我们已经了解了peewee、Sqlalchemy等众ORM框架了,今天我们继续介绍一款个性独特的ORM框架,它就是Pony。怎么样,是不是大名鼎鼎,未见其人,先闻其声,不得不说,这个ORM库的名字起的是真的好,但是其实际使用体验怎么样呢?我们一起来看看吧。
2、快速开始
2.1、安装Pony
pip install pony
2.2、链接数据库
新建文件pony_demo.py并输入以下代码:
from pony.orm import *
db = Database()
db.bind('sqlite','mydb.db',create_db=True)
直接执行代码:python pony_demo.py,你会发现,pony自动帮我们在当前文件夹下创建了一个数据库文件mydb.db。这就是create_db参数的作用,当数据库不存在的时候自动帮我们创建。
2.3、创建模型类(表)
在实际开发中,比如在Django、Flask、FastApi中都是用模型类来描述一个表的结构的。Pony也和其他ORM一样使用模型类来定义表结构,但是其写法和其他ORM框架稍有区别。
from pony.orm import *
db = Database()
db.bind('sqlite','mydb.db',create_db=True)
# 定义一个表:person
class Person(db.Entity):
_table_ = 'person' # 表名
# 当我们不定义主键ID的时候,pony会和大多数orm框架一样自动帮我们补全
# id = PrimaryKey(int, auto = True)
name = Required(str, 30, default = "未知")
age = Optional(int)
car = Set('Car') # 以集合的形式关联Car表,即一个人多个车
class Car(db.Entity):
_table_ = 'car'
name = Required(str)
typa = Required(str)
owner = Required(Person) # 关联Person表,即一个车的主人只有一个
if __name__ == '__main__':
# 1.查看表结构
show(Car)
如上,你会看到,不同于其他ORM框架的字段声明,Pony使用了必选(Required)和可选(Optional)以及表关联的这种方式。
执行如上代码,我们就能看到Car表的表结构:
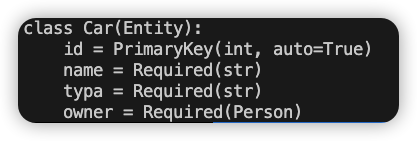
主键ID是Pony帮我们自动添加的,且自增。
此时的数据库中还未创建表;
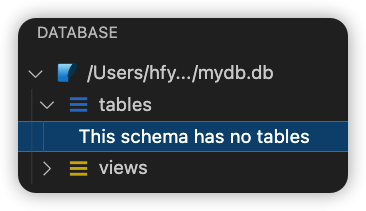
2.4、将表映射到数据库
以上内容我们只是定义了表结构(模型),现在我们需要将表映射到数据中去。
if __name__ == '__main__':
# 1.查看表结构
# show(Car)
# 2.将模型类映射到数据库,以表的形式展现
db.generate_mapping(create_tables=True) # 如果表存在则对表结构进行更新,如果不存在则创建
代码执行后查看数据库状态:
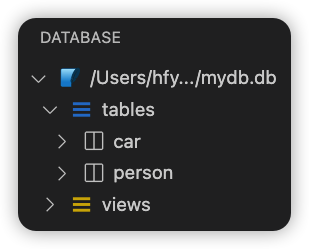
此时,我们就可以对数据库表进行读写操作了。
为了方便数据库的连接(db_session)管理,我们后续都使用pony为我们提供的db_session对数据库连接进行管理。(如此一来,我们不需要关注数据库的session建立和关闭,只需要专注于业务本身即可。)
2.5、CRUD之C
这里我们使用db_session对会话进行优雅管理,然后创建一个函数,在函数中实现对person的创建。
...
@db_session
def create_person(name,age):
perObj = Person(name=name,age=age)
...
if __name__ == '__main__':
# 3.CRUD之C
db.generate_mapping(create_tables=True)
create_person('phyger',18)
执行代码后,我们查看下数据库的内容:
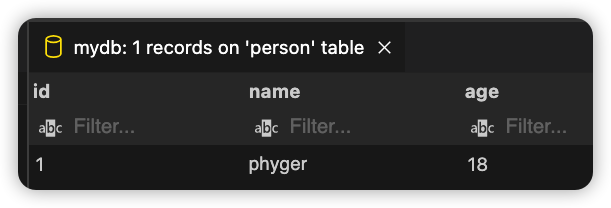
数据已经成功插入。
2.6、CRUD之R
参数C,我们在R中也是通过db_session对person表中的数据进行查询。
...
@db_session
def get_person(name):
persObj = Person.select(name=name)
print(persObj.first().age)
...
if __name__ == '__main__':
# 4.CRUD之R
db.generate_mapping(create_tables=True)
get_person('phyger')
代码执行结果:

2.7、CRUD之U
在完成了上述步骤后,我们继续对数据表中的数据进行更新操作。
...
@db_session
def put_person(name,new_name=None,new_age=None):
persObj = Person.select(name=name)
if new_name:
persObj.first().name=new_name
if new_age:
persObj.first().age=new_age
print('更新成功!')
...
if __name__ == '__main__':
# 5.CRUD之U
db.generate_mapping(create_tables=True)
get_person('phyger')
put_person('phyger',new_name='new_phyger')
get_person('phyger')
代码执行结果:
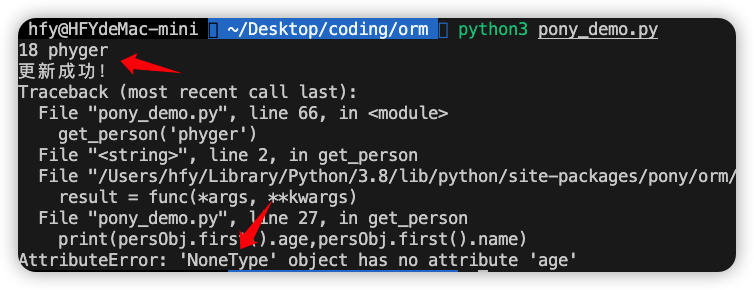
执行代码的最后一步报错了,为什么呢?因为我们修改了phyger的name后,还用旧的名称去查询,所以查询不到。
我们看下数据库中是否修改成功:
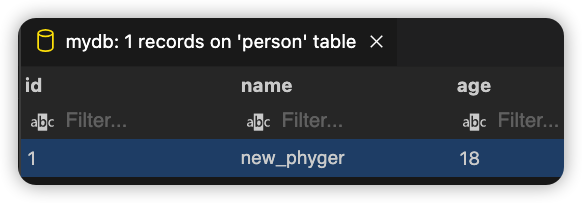
我们使用新名称查询即可查询成功了。
2.8、CRUD之D
在完成测试后,我们想要将数据表中的数据删除,怎么做呢?
我们先给数据表预置上11条数据:
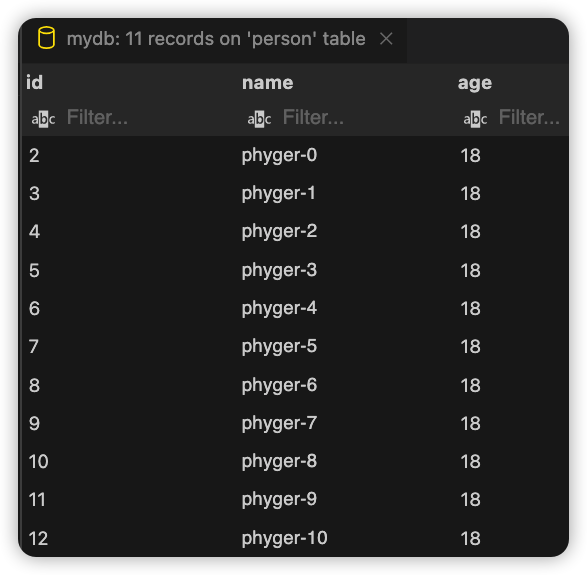
...
@db_session
def del_person(name):
delete(p for p in Person if p.name==name) # 根据名称进行删除
...
if __name__ == '__main__':
# 6.CRUD之D
db.generate_mapping(create_tables=True)
del_person('phyger-8')
指定删除name为phyger-8的数据,执行代码,刷新数据表查看结果:
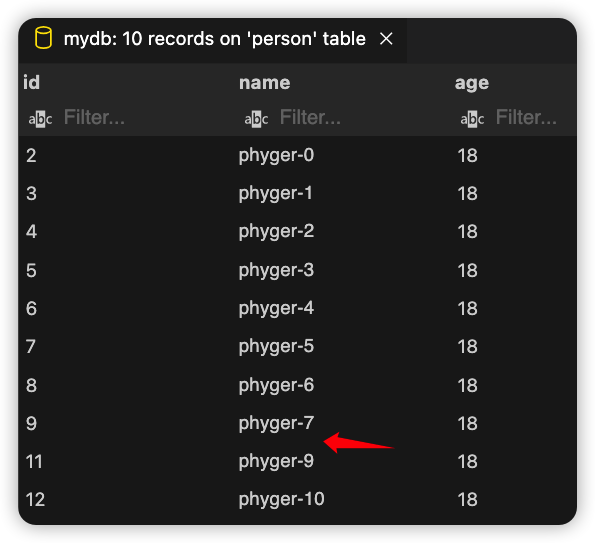
我们发现删除已经成功!
3、进阶
3.1、完善查询
上面的方法只能根据name进行查询,我们对其进行优化,使得能够使用id,name和age等参数进行查询。
@db_session
def get_person(name=None,id=None,age=None):
if name:
for p in Person.select(name=name):
print(p.id,p.name)
if id:
for p in Person.select(id=id):
print(p.id,p.name)
if age:
for p in Person.select(age=age):
print(p.id,p.name)
如此,我们即能够根据不同的查询参数进行查询了。
3.2、批量删除
我们根据上面的查询方法,如果根据年龄18查询将能够查询到所有的对象集合。类似的删除也可以如此来实现。
@db_session
def del_person(name=None,idd=None,age=None):
if name:
delete(p for p in Person if p.name==name)
if idd:
delete(p for p in Person if p.id==idd)
if age:
delete(p for p in Person if p.age==age)
if __name__ == '__main__':
# 批量删除
db.generate_mapping(create_tables=True)
del_person(age=18)
其实原本的方式也是支持批量删除的,这里只是增加了多种删除字段。
3.3、表结构变更如何实现
目前最新发布的pony 0.7版本还不支持数据库迁移(migrate),但是我们可以手动对表结构进行更改。0.8版本后将会支持数据库迁移,了解详情点击:/pony/pony/migrate。
3.4、分页
作为一个成熟的ORM框架,分页功能必不可少。
@db_session
def person_page(num,size):
PObj=Person.select()
for p in PObj.page(num,size):
print(p.name)
if __name__ == '__main__':
# 7.分页
db.generate_mapping(create_tables=True)
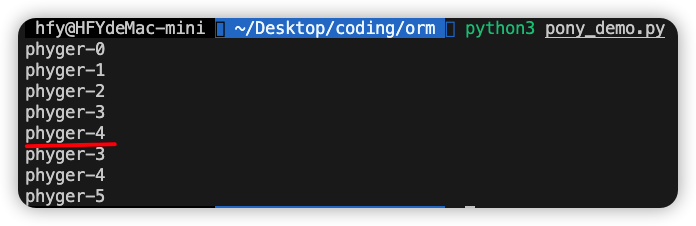
person_page(1,5) # 第一页,单页大小5 0到4
person_page(2,3) # 第二页,单页大小3 3,4,5
其中num是页码,size是每页的大小即pagesize。
3.5、表关联
上面,我们定义了person和car两张表,car的owner和person关联,使用外键id关联。现在我们就一起来看下如何使用。
普通创建car对象,即不做和person的关联。
@db_session
def create_car(name, typa, owner=None):
if owner:
carObj = Car(name=name, typa=typa, owner=owner)
else:
carObj = Car(name=name, typa=typa)
if __name__ == '__main__':
# 8、创建Car-1
db.generate_mapping(create_tables=True)
create_car(name='byd',typa='宋Pro-Dmi')
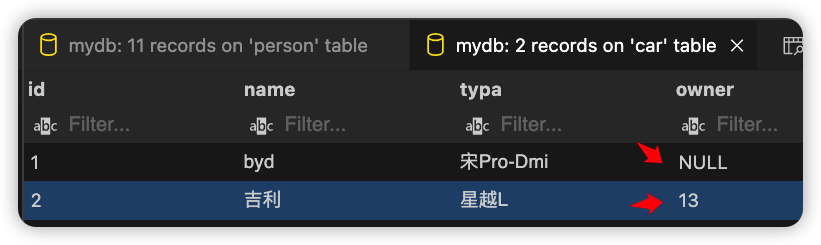
创建带person关联关系的car对象。
if __name__ == '__main__':
# 8、创建Car-2
db.generate_mapping(create_tables=True)
pp = get_person(id=14)
print(pp)
create_car(name='吉利',typa='星越L',owner=pp.id)
以上两段代码执行完成,查看car数据表内容:
联合查询,即根据用户查到其ID,在根据其ID查询名下的车。
@db_session
def get_car(name=None, id=None, owner=None):
if name:
for c in Car.select(name=name):
print(c.id, c.name)
if id:
for c in Car.select(id=id):
print(c.id, c.name)
if owner:
for c in Car.select(owner=owner):
print(c.id, c.name)
if __name__ == '__main__':
# 9、表关联的查询
db.generate_mapping(create_tables=True)
ps = get_person(name='phyger-0')
get_car(owner=ps.id)
代码执行结果:

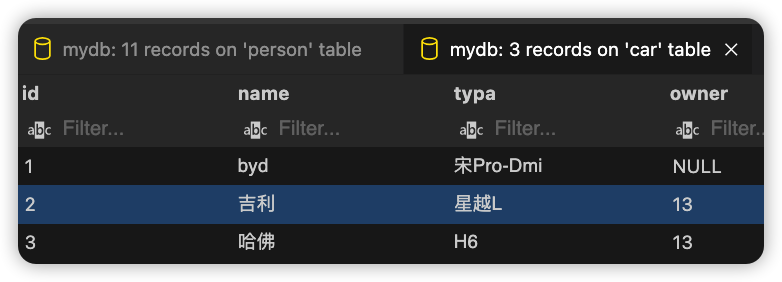
如上,我们得知phyger-0名下有两辆车,分别是吉利和哈佛。
Car数据表内容如下:
4、最后
相比peewee和sqlalchemy、pony确实存在一些不完善的地方,但是pony1.0仍然值得期待!
以上就是今天的全部内容了。


评论区